网盛创新研究院 - AI、区块链、云计算、大数据技术的研究与应用交流平台!

Related Info
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。
根据下列算法而建造每棵树 :
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用)。
随机森林的优点有 :
1)对于很多种资料,它可以产生高准确度的分类器;
2)它可以处理大量的输入变数;
3)它可以在决定类别时,评估变数的重要性;
4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计;
5)它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;
6)它提供一个实验方法,可以去侦测variable interactions;
7)对于不平衡的分类资料集来说,它可以平衡误差;
8)它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将资料视觉化非常有用;
9)使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料;
10)学习过程是很快速的。
1.分裂:在决策树的训练过程中,需要一次次的将训练数据集分裂成两个子数据集,这个过程就叫做分裂。
2.特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。
3.待选特征:在决策树的构建过程中,需要按照一定的次序从全部的特征中选取特征。待选特征就是在目前的步骤之前还没有被选择的特征的集合。例如,全部的特征是 ABCDE,第一步的时候,待选特征就是ABCDE,第一步选择了C,那么第二步的时候,待选特征就是ABDE。
4.分裂特征:接待选特征的定义,每一次选取的特征就是分裂特征,例如,在上面的例子中,第一步的分裂特征就是C。因为选出的这些特征将数据集分成了一个个不相交的部分,所以叫它们分裂特征。
要说随机森林,必须先讲决策树。决策树是一种基本的分类器,一般是将特征分为两类(决策树也可以用来回归,不过本文中暂且不表)。构建好的决策树呈树形结构,可以认为是if-then规则的集合,主要优点是模型具有可读性,分类速度快。
我们用选择量化工具的过程形象的展示一下决策树的构建。假设现在要选择一个优秀的量化工具来帮助我们更好的炒股,怎么选呢?
第一步:看看工具提供的数据是不是非常全面,数据不全面就不用。
第二步:看看工具提供的API是不是好用,API不好用就不用。
第三步:看看工具的回测过程是不是靠谱,不靠谱的回测出来的策略也不敢用啊。
第四步:看看工具支不支持模拟交易,光回测只是能让你判断策略在历史上有用没有,正式运行前起码需要一个模拟盘吧。
这样,通过将“数据是否全面”,“API是否易用”,“回测是否靠谱”,“是否支持模拟交易”将市场上的量化工具贴上两个标签,“使用”和“不使用”。
上面就是一个决策树的构建,逻辑可以用图1表示:
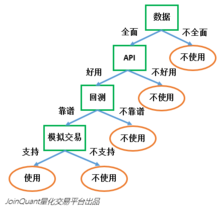 图1.决策树构建1
图1.决策树构建1
在图1中,绿颜色框中的“数据”“API”“回测”“模拟交易”就是这个决策树中的特征。如果特征的顺序不同,同样的数据集构建出的决策树也可能不同。特征的顺序分别是“数据”“API”“回测”“模拟交易”。如果我们选取特征的顺序分别是“数据”“模拟交易”“API”“回测”,那么构建的决策树就完全不同了。
可以看到,决策树的主要工作,就是选取特征对数据集进行划分,最后把数据贴上两类不同的标签。如何选取最好的特征呢?还用上面选择量化工具的例子:假设现在市场上有100个量化工具作为训练数据集,这些量化工具已经被贴上了“可用”和“不可用”的标签。
我们首先尝试通过“API是否易用”将数据集分为两类;发现有90个量化工具的API是好用的,10个量化工具的API是不好用的。而这90个量化工具中,被贴上“可以使用”标签的占了40个,“不可以使用”标签的占了50个,那么,通过“API是否易用”对于数据的分类效果并不是特别好。因为,给你一个新的量化工具,即使它的API是易用的,你还是不能很好贴上“使用”的标签。
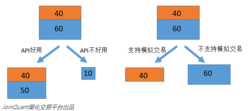 图2.决策树的构建2
图2.决策树的构建2
再假设,同样的100个量化工具,通过“是否支持模拟交易”可以将数据集分为两类,其中一类有40个量化工具数据,这40个量化工具都支持模拟交易,都最终被贴上了“使用”的标签,另一类有60个量化工具,都不支持模拟交易,也都最终被贴上了“不使用”的标签。如果一个新的量化工具支持模拟交易,你就能判断这个量化工具是可以使用。我们认为,通过“是否支持模拟交易”对于数据的分类效果就很好。
在现实应用中,数据集往往不能达到上述“是否支持模拟交易”的分类效果。所以我们用不同的准则衡量特征的贡献程度。主流准则的列举3个:ID3算法(J. Ross Quinlan于1986年提出)采用信息增益最大的特征;C4.5算法(J. Ross Quinlan于1993年提出)采用信息增益比选择特征;CART算法(Breiman等人于1984年提出)利用基尼指数最小化准则进行特征选择。
编辑
决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取。
1.数据的随机选取:
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。
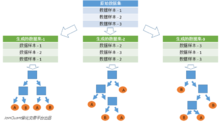 图3.数据的随机选取
图3.数据的随机选取
2.待选特征的随机选取
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
下图中,蓝色的方块代表所有可以被选择的特征,也就是目前的待选特征。黄色的方块是分裂特征。左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征(别忘了前文提到的ID3算法,C4.5算法,CART算法等等),完成分裂。右边是一个随机森林中的子树的特征选取过程。
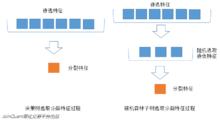 图4.待选特征的随机选取
图4.待选特征的随机选取


