网盛创新研究院 - AI、区块链、云计算、大数据技术的研究与应用交流平台!

Related Info
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。(这反过来又应当由多个相关的因变量预测的多元线性回归区别,而不是一个单一的标量变量。)
回归分析中有多个自变量:这里有一个原则问题,这些自变量的重要性,究竟谁是最重要,谁是比较重要,谁是不重要。所以,spss线性回归有一个和逐步判别分析的等价的设置。
原理:是F检验。spss中的操作是“分析”~“回归”~“线性”主对话框方法框中需先选定“逐步”方法~“选项”子对话框
如果是选择“用F检验的概率值”,越小代表这个变量越容易进入方程。原因是这个变量的F检验的概率小,说明它显著,也就是这个变量对回归方程的贡献越大,进一步说就是该变量被引入回归方程的资格越大。究其根本,就是零假设分水岭,例如要是把进入设为0.05,大于它说明接受零假设,这个变量对回归方程没有什么重要性,但是一旦小于0.05,说明,这个变量很重要应该引起注意。这个0.05就是进入回归方程的通行证。
下一步:“移除”选项:如果一个自变量F检验的P值也就是概率值大于移除中所设置的值,这个变量就要被移除回归方程。spss回归分析也就是把自变量作为一组待选的商品,高于这个价就不要,低于一个比这个价小一些的就买来。所以“移除”中的值要大于“进入”中的值,默认“进入”值为0.05,“移除”值为0.10
如果,使用“采用F值”作为判据,整个情况就颠倒了,“进入”值大于“移除”值,并且是自变量的进入值需要大于设定值才能进入回归方程。这里的原因就是F检验原理的计算公式。所以才有这样的差别。
结果:如同判别分析的逐步方法,表格中给出所有自变量进入回归方程情况。这个表格的标志是,第一列写着拟合步骤编号,第二列写着每步进入回归方程的编号,第三列写着从回归方程中剔除的自变量。第四列写着自变量引入或者剔除的判据,下面跟着一堆文字。
这种设置的根本目的:挑选符合的变量,剔除不符合的变量。
注意:spss中还有一个设置,“在等式中包含常量”,它的作用是如果不选择它,回归模型经过原点,如果选择它,回归方程就有常数项。这个选项选和不选是不一样的。
在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。这些模型被叫做线性模型。最常用的线性回归建模是给定X值的y的条件均值是X的仿射函数。不太一般的情况,线性回归模型可以是一个中位数或一些其他的给定X的条件下y的条件分布的分位数作为X的线性函数表示。像所有形式的回归分析一样,线性回归也把焦点放在给定X值的y的条件概率分布,而不是X和y的联合概率分布(多元分析领域)。
线性回归是回归分析中第一种经过严格研究并在实际应用中广泛使用的类型。这是因为线性依赖于其未知参数的模型比非线性依赖于其位置参数的模型更容易拟合,而且产生的估计的统计特性也更容易确定。
线性回归模型经常用最小二乘逼近来拟合,但他们也可能用别的方法来拟合,比如用最小化“拟合缺陷”在一些其他规范里(比如最小绝对误差回归),或者在桥回归中最小化最小二乘损失函数的惩罚.相反,最小二乘逼近可以用来拟合那些非线性的模型.因此,尽管“最小二乘法”和“线性模型”是紧密相连的,但他们是不能划等号的。
一般来说,线性回归都可以通过最小二乘法求出其方程,可以计算出对于y=bx+a的直线。
虽然不同的统计软件可能会用不同的格式给出回归的结果,但是它们的基本内容是一致的。以STATA的输出为例来说明如何理解回归分析的结果。在这个例子中,测试读者的性别(gender),年龄(age),知识程度(know)与文档的次序(noofdoc)对他们所觉得的文档质量(relevance)的影响。
输出:
Source | SS df MS Number of obs = 242
-------------+------------------------------------------ F ( 4, 237) = 2.76
Model | 14.0069855 4 3.50174637 Prob > F = 0.0283
Residual | 300.279172 237 1.26700072 R-squared = 0.0446
------------- +------------------------------------------- Adj R-squared = 0.0284
Total | 314.286157 241 1.30409194 Root MSE = 1.1256
------------------------------------------------------------------------------------------------
relevance | Coef. Std. Err. t P>|t| Beta
---------------+--------------------------------------------------------------------------------
gender | -.2111061 .1627241 -1.30 0.196 -.0825009
age | -.1020986 .0486324 -2.10 0.037 -.1341841
know | .0022537 .0535243 0.04 0.966 .0026877
noofdoc | -.3291053 .1382645 -2.38 0.018 -.1513428
_cons | 7.334757 1.072246 6.84 0.000 .
-------------------------------------------------------------------------------------------
这个输出包括以下几部分。左上角给出方差分析表,右上角是模型拟合综合参数。下方的表给出了具体变量的回归系数。方差分析表对大部分的行为研究者来讲不是很重要,不做讨论。在拟合综合参数中, R-squared 表示因变量中多大的一部分信息可以被自变量解释。在这里是4.46%,相当小。
一般地,要求这个值大于5%。对大部分的行为研究者来讲,最重要的是回归系数。年龄增加1个单位,文档的质量就下降 -.1020986个单位,表明年长的人对文档质量的评价会更低。这个变量相应的t值是 -2.10,绝对值大于2,p值也<0.05,所以是显著的。结论是,年长的人对文档质量的评价会更低,这个影响是显著的。相反,领域知识越丰富的人,对文档的质量评估会更高,但是这个影响不是显著的。这种对回归系数的理解就是使用回归分析进行假设检验的过程。
![]()
,
![]()
,
![]()
其中
![]()
,代表y的平方和;
![]()
是相关系数,代表变异被回归直线解释的比例;
![]()
就是不能被回归直线解释的变异,即SSE。
根据回归系数与直线斜率的关系,可以得到等价形式:

,其中b为直线斜率
![]()
,其中
![]()
是实际测量值,
![]()
是根据直线方程算出来的预测值
编辑
法1:用
![]()

法2:把斜率b带入
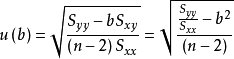

线性回归有很多实际用途。分为以下两大类:
如果目标是预测或者映射,线性回归可以用来对观测数据集的和X的值拟合出一个预测模型。当完成这样一个模型以后,对于一个新增的X值,在没有给定与它相配对的y的情况下,可以用这个拟合过的模型预测出一个y值。
给定一个变量y和一些变量X1,...,Xp,这些变量有可能与y相关,线性回归分析可以用来量化y与Xj之间相关性的强度,评估出与y不相关的Xj,并识别出哪些Xj的子集包含了关于y的冗余信息。
一条趋势线代表着时间序列数据的长期走势。它告诉我们一组特定数据(如GDP、石油价格和股票价格)是否在一段时期内增长或下降。虽然我们可以用肉眼观察数据点在坐标系的位置大体画出趋势线,更恰当的方法是利用线性回归计算出趋势线的位置和斜率。
有关吸烟对死亡率和发病率影响的早期证据来自采用了回归分析的观察性研究。为了在分析观测数据时减少伪相关,除最感兴趣的变量之外,通常研究人员还会在他们的回归模型里包括一些额外变量。例如,假设我们有一个回归模型,在这个回归模型中吸烟行为是我们最感兴趣的独立变量,其相关变量是经数年观察得到的吸烟者寿命。研究人员可能将社会经济地位当成一个额外的独立变量,已确保任何经观察所得的吸烟对寿命的影响不是由于教育或收入差异引起的。然而,我们不可能把所有可能混淆结果的变量都加入到实证分析中。例如,某种不存在的基因可能会增加人死亡的几率,还会让人的吸烟量增加。因此,比起采用观察数据的回归分析得出的结论,随机对照试验常能产生更令人信服的因果关系证据。当可控实验不可行时,回归分析的衍生,如工具变量回归,可尝试用来估计观测数据的因果关系。
资本资产定价模型利用线性回归以及Beta系数的概念分析和计算投资的系统风险。这是从联系投资回报和所有风险性资产回报的模型Beta系数直接得出的。
线性回归是经济学的主要实证工具。例如,它是用来预测消费支出,固定投资支出,存货投资,一国出口产品的购买,进口支出,要求持有流动性资产,劳动力需求、劳动力供给。


