网盛创新研究院 - AI、区块链、云计算、大数据技术的研究与应用交流平台!

原文来自:特大号

今年是彻底的火了,这不是梦话,而是大势所趋,AI 已经渗透到各行各业。

无论是哪类客户,都表现出了对 AI 的“强烈意愿”,毕竟谁也不想被时代抛弃。
所以问题来了:现阶段考验客户的问题,不在于是否部署人工智能 (AI),而是如何部署人工智能?
然而,当大家怀着无限憧憬,迈向人工智能第一步的时候,“坑”就已经静静地等在那里了。
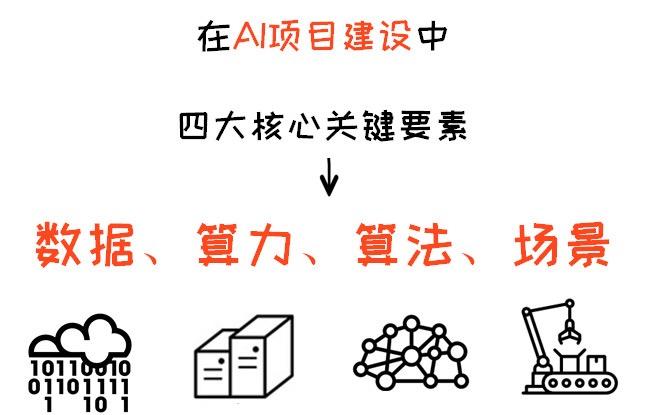
无论何种项目、如何部署,都绕不开以上这四大关键要素,而那些“坑”,就隐藏在这些要素里。
1. 数据的坑

现在一提到人工智能,大家就说,必须要有“海量数据”。没错,“数据”对于 AI 来说至关重要,没有数据,一切是空谈。
我们来看一下整个 AI 处理的大致流程就知道,数据就像婴儿奶粉一样,只有持续不断地“喂”,才能让机器完成不断学习,变得智能。构建模型、训练数据,训练使用的数据集越大、质量越好,训练出来的AI模型就越“聪明”。但是,深度学习的模型训练决定了奶粉不能一次喂,今天吃了,明天还要吃,做不到“一次喂饱完事”。
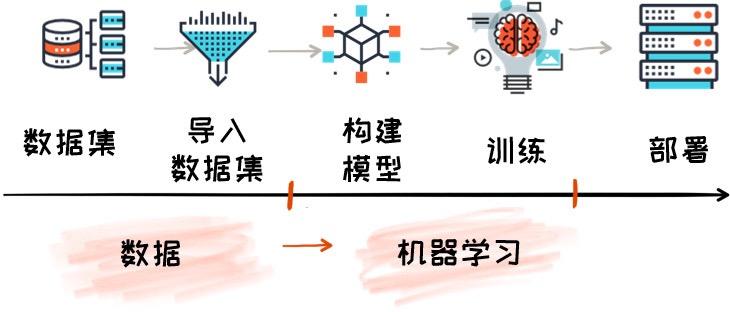
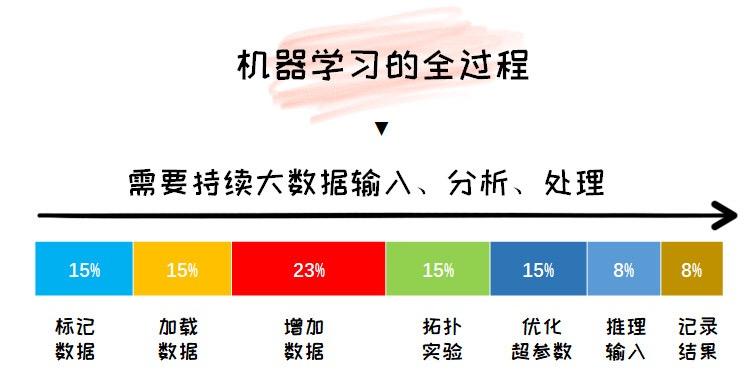
我们更应该重视的是,海量数据的“消化过程”。
所以:

2. 算法的坑

我们经常被忽悠,一提到人工智能的算法,就是必须是深度学习,这是一个常识性错误。我们来看一下,人工智能、机器学习、深度学习三者关系如下:
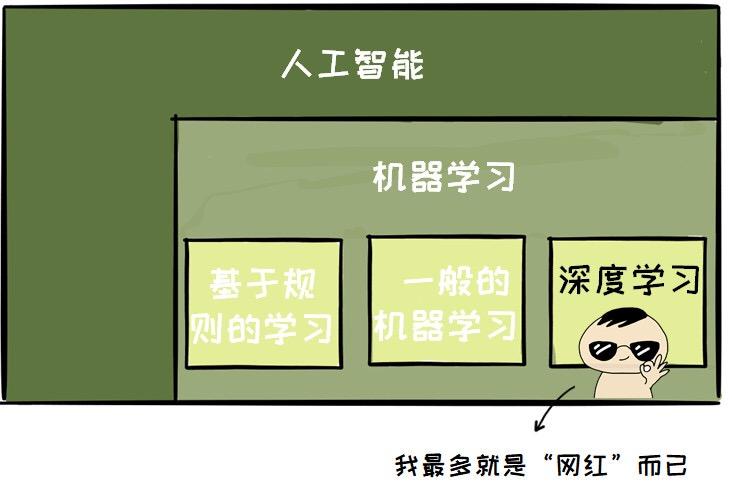
其实,AI 领域的主流技术路径有三种:①深度学习;②一般的机器学习 ;③基于规则的学习。这三种技术路径之间的关系与其说是彼此竞争或替代,更不如说是互补。
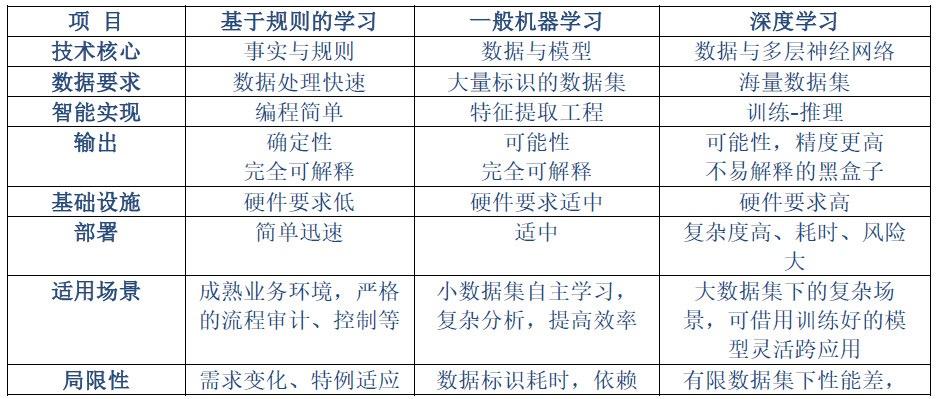
所以,客户面对的技术路径,不只深度学习一条道,无论是传统推理、机器学习,或是它们的融合 ,都是可选项。
举个例子:
中国银联电子商务与电子支付国家工程实验室
推进银行卡反欺诈技术研究
刚开始,发现
1、如果只使用机器学习,将面临对序列化交易特征学习能力不足问题
2、如果只用深度学习,将面临单笔交易内特征学习能力有限的问题
最终研究结论是:两种技术融合才是最好的方案,并采用兼容性极大的 CPU 计算平台,完美实现 GBDT→GRU→RF 三明治结构欺诈侦测模型架构。
所以:

3. 算力的坑

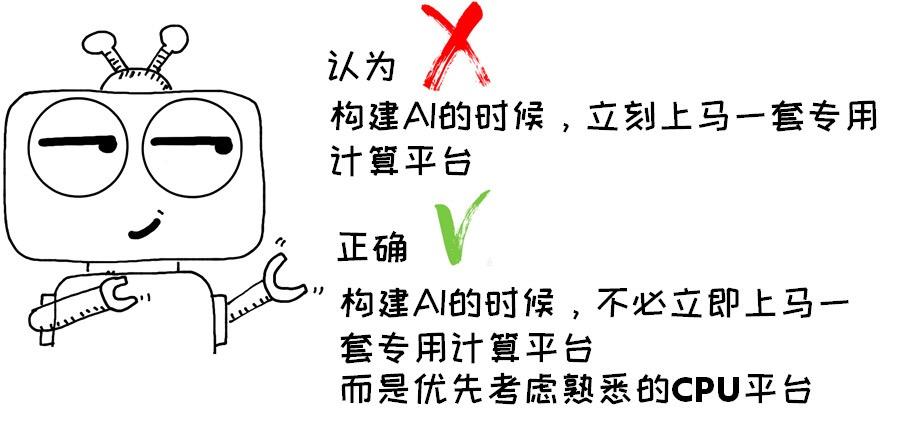
高算力,也是 AI 的核心关键要素之一。现在一提到人工高智能就立刻想上一套新的专用硬件计算平台。误认为现有的数据中心基础设施达不到 AI 对算力的要求,必须靠专用计算平台才能匹配,这是很严重的误导!
正确的姿势是:现阶段应该利用现有的数据中心基础设施,应该利用现有的、你熟悉的处理器平台,以最低的成本部署人工智能。相比另起炉灶、寻其他计算平台的方法 ,用时更短 、风险更低、性价比更高 。为什么呢?
① 标准 CPU 平台,今非昔比,完全能够胜任 AI 所有应用。
② 最小成本,做最大的事,利用现有的 CPU 平台,无需大量额外投资。现在人工智能属于“试错阶段”,同时技术也在快速演变和迭代,如果另起炉灶,得不偿失。
③ 最熟悉的平台,做最靠谱的事。CPU 平台,你用了这么多年用熟悉且信任的平台,构建“激进”的 AI 项目本身就是一个绝好的平衡,让技术风险可控。
所以:
4. 场景的坑

用一套专用的 AI 方案绑架客户意味着,不管啥场景、不管啥应用统统只推荐一套方案。不灵活是专用 AI 硬件平台的弊端之一, 而 CPU 平台有极强的灵活性,满足上层 AI 场景的百变需求。
所以:

数据、算法、算力、场景,踩完4大关键要素的坑儿,我们发现 AI 的落地,需要一个灵活的、成熟的、高性价比的平台:
① 能对数据进行持续分析和利用
② 能让各种AI算法都愉快work起来
③ 能提供与训练需求相匹配的算力
④ 能灵活适配各类AI应用场景
……
而这个平台,可能早已拥有,或者,你可以轻松升级。
英特尔® 至强® 可扩展处理器

对,用你熟悉的硬件平台,再导入英特尔在AI软件层面的最新优化组合,比如:框架、工具、库,就能立刻盘活你的数据中心,承载任何AI高强度应用。
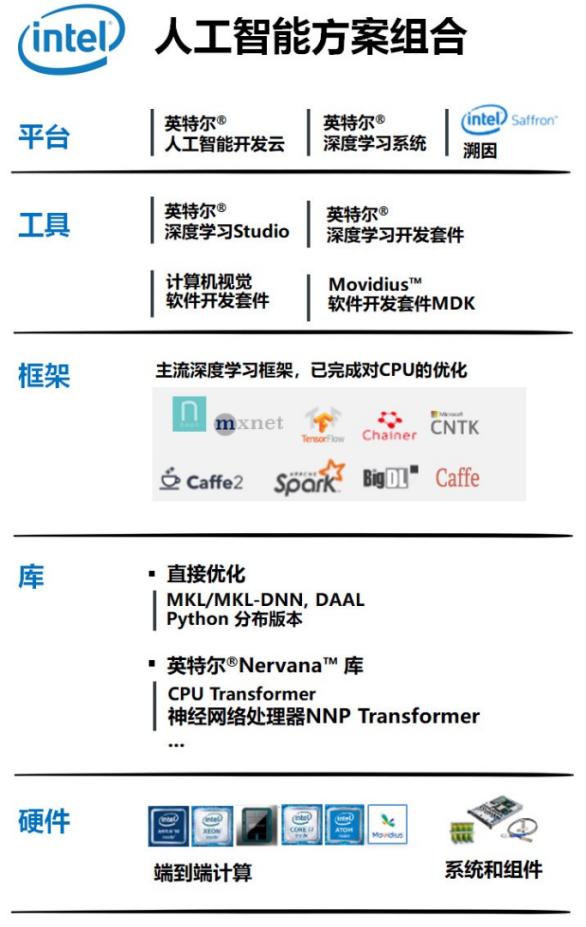
很多客户已经基于这个平台开始了大规模 AI 应用,比如:
中国银联电子商务与电子支付国家工程实验室
基于英特尔至强平台、Cloudera CDH、Apache Spark和BigDL 构建的人工神经网络风控系统,与基于规则的风控系统相比,能提升高达 20% 的正确度,并具备 60% 的涵盖率,从而在短短数月内就达到了最佳训练模式。该实验室的 GBDT →GRU→RF 三明治结构欺诈侦测模型 ,在至强平台以及 BigDL、面向英特尔架构优化的 TensorFlow、英特尔 MKL -DNN 和 DAAL 等框架和工具的支持下,效率也得以大幅提升 。
京东
在基于至强的集群上将图像检测和提取方案升级为英特尔开源的 BigDL,其性能比原有的基于专有架构的解决方案提升了 3.83 倍。
由于 BigDL 允许以 Scala 或 Python 编写深度学习应用程序,也为开发、运维人员带来了极大便利。
UCloud
基于至强平台构建的 AI 在线服务在搭配面向英特尔架构优化的 Caffe 框架后,同时运行的线程数量显著增加,整体执行性能提高了 10 倍以上。
它在人脸表情识别的测试中,在并发数为 8-16 节点时,性能可与专用架构的平台相媲美。
GE 医疗集团
在使用至强处理器的四个或四个以下的专用内核对 CT 影像进行分类测试时发现,由英特尔深度学习开发工具包和 MKL-DNN 生成的优化代码,相比在同样系统上运行的基准 TensorFlow 模型,在推理吞吐量上平均提高了 14 倍。
众里寻它千百度,蓦然回首,AI 就在,自家机房灯火阑珊处。
从CPU平台开始,从熟悉和信任的平台开始,开始你的 AI 之旅吧!


